What if we don’t have an asset hierarchy unified across applications?
This question is a common state for most industrial organizations on their digitalization journey. Investments at the site level are often absent, since operators and process engineers are already fluent in the unique naming convention of their process tags. Replicating the structure in the ERP system is not feasible, as it is either too dated or not granular enough. Yet, to increase operational efficiency, an organization must unify OT, IT, and engineering data so it can be easily understood at both a site and enterprise level. An asset hierarchy provides a launching point to unify industrial data in a knowledge graph and scale industrial AI use cases.
What is an asset hierarchy
70% of industrial organizations struggle to use operational data for analysis1. While existing point solutions deliver targeted analysis and impact, the unstructured OT data landscape has prevented this impact from scaling across additional sites or use cases. The purpose of an asset hierarchy is to normalize and structure operational data, removing the need to understand the unique naming conventions of siloed systems and simplifying the use of OT data for analysis at scale.
An asset hierarchy provides a logical, tree-like structure representing an industrial organization’s physical assets. It contains parent-child relationships between units and systems, systems and equipment, and components and their parts. These relationships can represent a single unit or production line and span from the enterprise to individual parts.
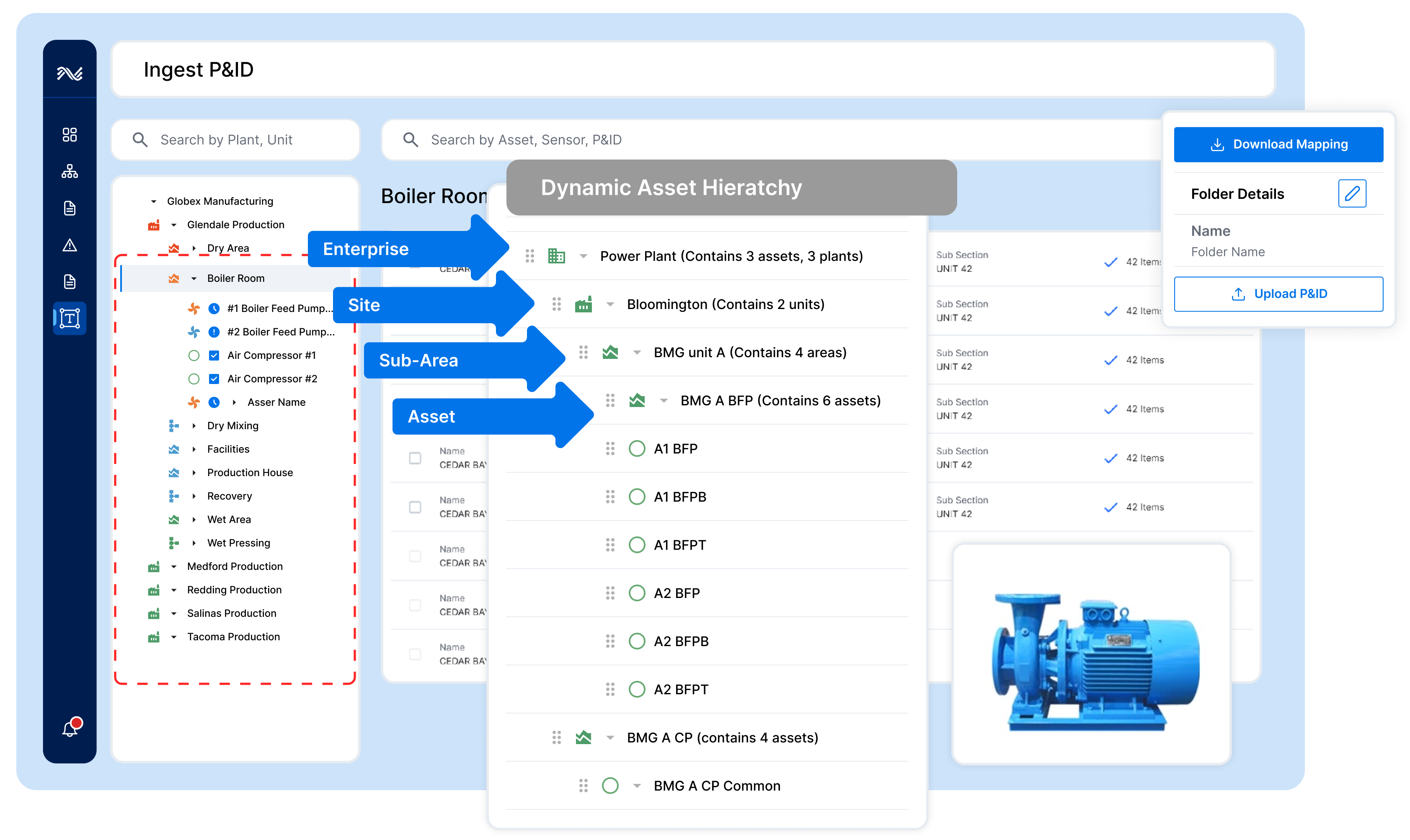
Users can drill up or down the hierarchy to gain the appropriate level of visibility. A process engineer may be interested in a unit-level analysis, while a reliability engineer may be interested in a specific component of a piece of equipment. An asset hierarchy provides a foundation for many industrial users to access the same real-time information in a context everyone can understand. ISA95 and ISO 14224 standards outline this structure in more detail and should be adopted and adapted to an organization’s specific needs. The asset hierarchy provides the foundation for combining OT data with IT and engineering data into an industrial knowledge graph.
How does an industrial knowledge graph create value?
Traditionally, asset hierarchies have primarily targeted reliability use cases. When offered as an extension to existing historians, they provide a structured view of time series data, so industrial organizations can move from preventive to predictive maintenance with physics-based analytics models and health scores. While valuable, this use case is a narrow view of the potential impact of an asset hierarchy.
To expand the scope of use cases that an asset hierarchy can address, an industrial knowledge graph can extend beyond time series in the historian and incorporate data from IoT platforms and edge devices, CMMS, ERP, engineering drawings and diagrams such as P&IDs, and more. These additional data sources must be accessible through a composable approach so new use cases drive the integration of these sources. With an industrial knowledge graph, organizations have been able to unlock the following use cases:
- Industrial collaboration – Troubleshoot processes or perform a root cause analysis by unifying the view of asset information, time series, P&IDs, and predictive models in a live collaboration workspace. With rolled-up health scores and predictive analytics easily accessible through the knowledge graph, teams can quickly find the information needed for analysis.
- OT / IT convergence – With unified OT, IT, and engineering data, open and robust APIs can extract the relevant data and relationships between the data. The knowledge graph normalizes industrial data and allows it to be integrated with ERP, financial, and supply chain data in an existing data lake or lakehouse. A real-time view of operations increases visibility, provides understanding to business users, and enables more agile responses to changing product demand.
- Performance analytics – Generate actionable KPIs by combining the asset hierarchy with time series, IIoT, and CMMS data using out-of-the-box industrial calculations for metrics such as OEE, process and energy efficiency, mass and energy balance, mean-time-between-failure, mean-time-to-repair, and more.
- AI-driven predictive analytics – Combine an asset hierarchy relationships, equipment failure mode and effects analysis (FMEA), and an MLOps studio with pre-built industrial models to identify potential equipment failures previously undetectable by traditional monitoring techniques.
- Process optimization – Use AI models to tune process control parameters to maximize throughput or energy efficiency. Quickly query the industrial knowledge graph to discover a normalized view of the necessary process variables to optimize systems such as rolling mills, furnaces, grinding mills, distillation processes, etc.
- Industrial copilots – Combining industrial LLMs with a knowledge graph lets purpose-built, generative AI copilots simplify the generation of insights with site or company-specific information. Using predictive and generative AI together unlocks compositional AI, applying the right AI to right use cas
Why aren’t industrial knowledge graphs more prevalent in modern-day manufacturing?
Knowledge graphs aren’t new. They have existed for 15+ years and are already prevalent in helping financial services, retail, healthcare, and other industries improve business operations. With the proliferation of generative AI, the importance of knowledge graphs has only accelerated as they are primarily regarded as the most efficient way, in combination with retrieval augmented generation (RAG), to safely and securely apply generative AI to company-specific data. Given all the momentum and potential of knowledge graphs for industrial use cases, the adoption within industrial operations remains surprisingly low. Here are some of the most common challenges manufacturing and energy organizations are facing when building industrial knowledge graphs:
- Operational data is messy and unstructured – Unlike the other businesses mentioned above, operational data is rarely in tables and rows. Many systems have a subset of the required operational data for a comprehensive knowledge graph, and are insufficient to solve identified use cases. Further, most existing knowledge graph technologies lack connectivity to industrial sources and protocols. However, a dynamic, historian-agnostic asset hierarchy can structure OT data and provide the foundation for an industrial knowledge graph.
- Many asset hierarchy solutions create new silos – For an asset hierarchy to provide structure for operational data, it must be comprehensive and vendor-agnostic. For example, asset hierarchy using an existing historian can only access the data within that historian. This creates challenges from an architectural standpoint, such as how to incorporate data from multiple historians or existing IoT solutions.
- Existing asset hierarchies are rigid – Operations are dynamic. Sites add new equipment, replace old equipment, and add new monitoring sources (images and video) and devices. To keep the OT data landscape up to date, maintaining the asset hierarchy and knowledge graph must be simple and able to be owned at the site level.
- Structuring OT data is manual – Mapping thousands of tags to their associated assets with unique naming conventions is time-consuming, manual, and requires site-level domain expertise. Additionally, every type of equipment must be defined with the expected channels for each tag. Defining assets and mapping tags is only for time series data; further mapping must still be done for CMMS records, production orders, P&IDs, etc. Automation and industrial-specific equipment templates are a requirement to make this achievable at scale.
- Prior approaches lack composability – The business case takes priority. Trying to structure decades of legacy equipment and systems into a single unified industrial knowledge graph sounds daunting. Industrial organizations must be able to start with single units or production lines and grow at the pace the business can absorb. This requires a composable approach where new data sources can be added when new use cases are identified, and the existing structure can be easily modified.
What is required to build an industrial knowledge graph?
At the highest level, many requirements for an industrial knowledge graph are standard within industrial data operations products, like IRIS Foundry. A dynamic, historian-agnostic asset hierarchy offers a straightforward path to structuring OT data and creates the foundation for an industrial knowledge graph. The asset hierarchy can automatically populate the knowledge graph with data and relationships defined within the hierarchy. Then, new data sources and relationships can be modeled as the business case requires. To create a dynamic asset hierarchy and subsequent knowledge graph, the following is required:

- Industrial source and protocol connectivity – To build an asset hierarchy, a historian is just one aspect of operational data. Additional information from IoT solutions, edge devices, reliability systems, and more must also be accessible. To build an industrial knowledge graph, information from IT and engineering sources such as ERP, CMMS, offline spreadsheets, engineering drawings and documents, existing data lakes, and more will be required. SymphonyAI addresses this accessibility challenge with pre-built connectors to over 100 industrial sources and protocols such as OPC UA and DA, Modbus, MQTT, Azure IoT Hub, InfluxDB, Kafka, OSI PI, IP.21, and an ODBC connector to quickly develop new integrations.
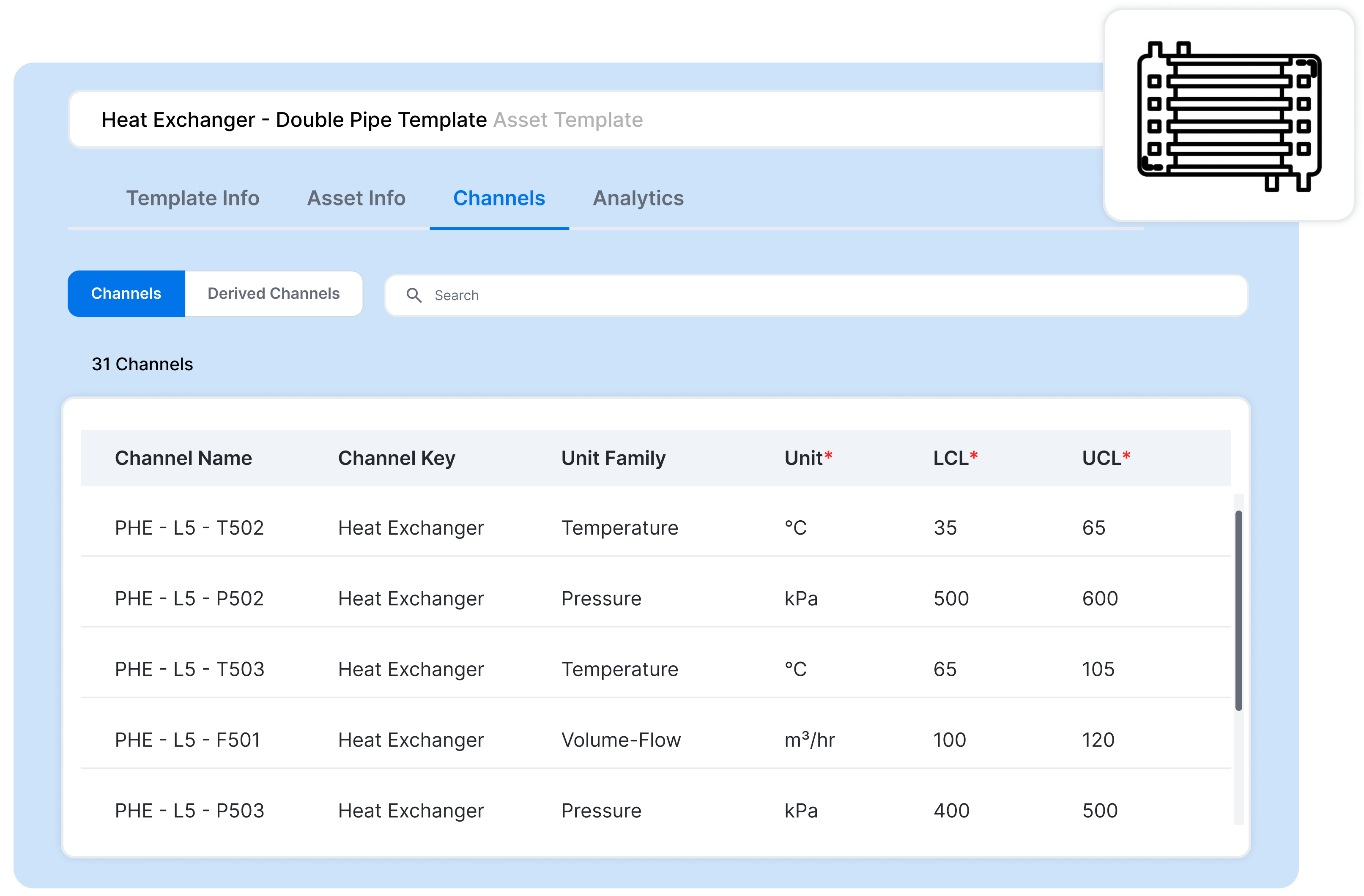
- Pre-defined Asset and Process Templates – To structure OT data at scale, equipment and processes must be defined with profiles that logically represent the physical asset. For example, heat exchangers have expected inflow and outflow temperature and pressure measurements and common failure modes such as indications of fouling, internal leaks, or scaling. Manually defining the digital asset profiles and failure modes can take weeks or months. To reduce this effort, SymphonyAI has 90+ pre-defined templates for common industrial equipment and their failure modes. Some examples include various types of heat exchangers, compressors, turbines, gearboxes, and more. These templates can be modified and replicated to normalize equipment across processes.
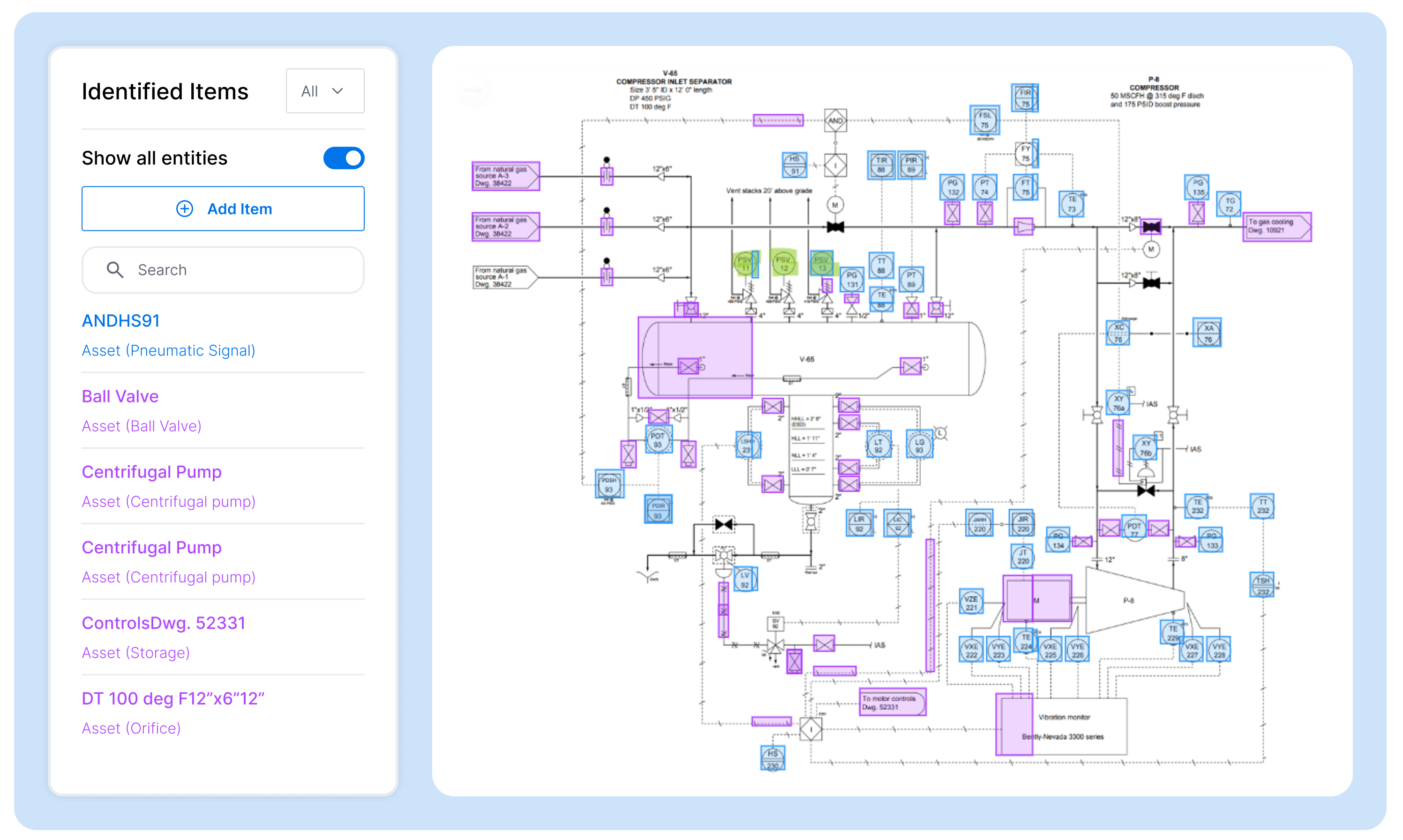
- AI-powered mapping of tags and hierarchy creation – Once accessible data and defined equipment profiles are in place, relevant asset tags must then be mapped to their associated assets, and the relationships between them must be established. Manually mapping thousands of tags to hundreds of assets and then structuring the relationships between these assets is not scalable. SymphonyAI accelerates mapping via AI-powered contextualization by identifying patterns between unique naming conventions and their associated assets. Taking this further, the relationships between assets can be extracted through P&ID ingestion, identifying assets and their relationships from these drawings. Combining these two processes automates building the hierarchy and mapping OT data to their assets.
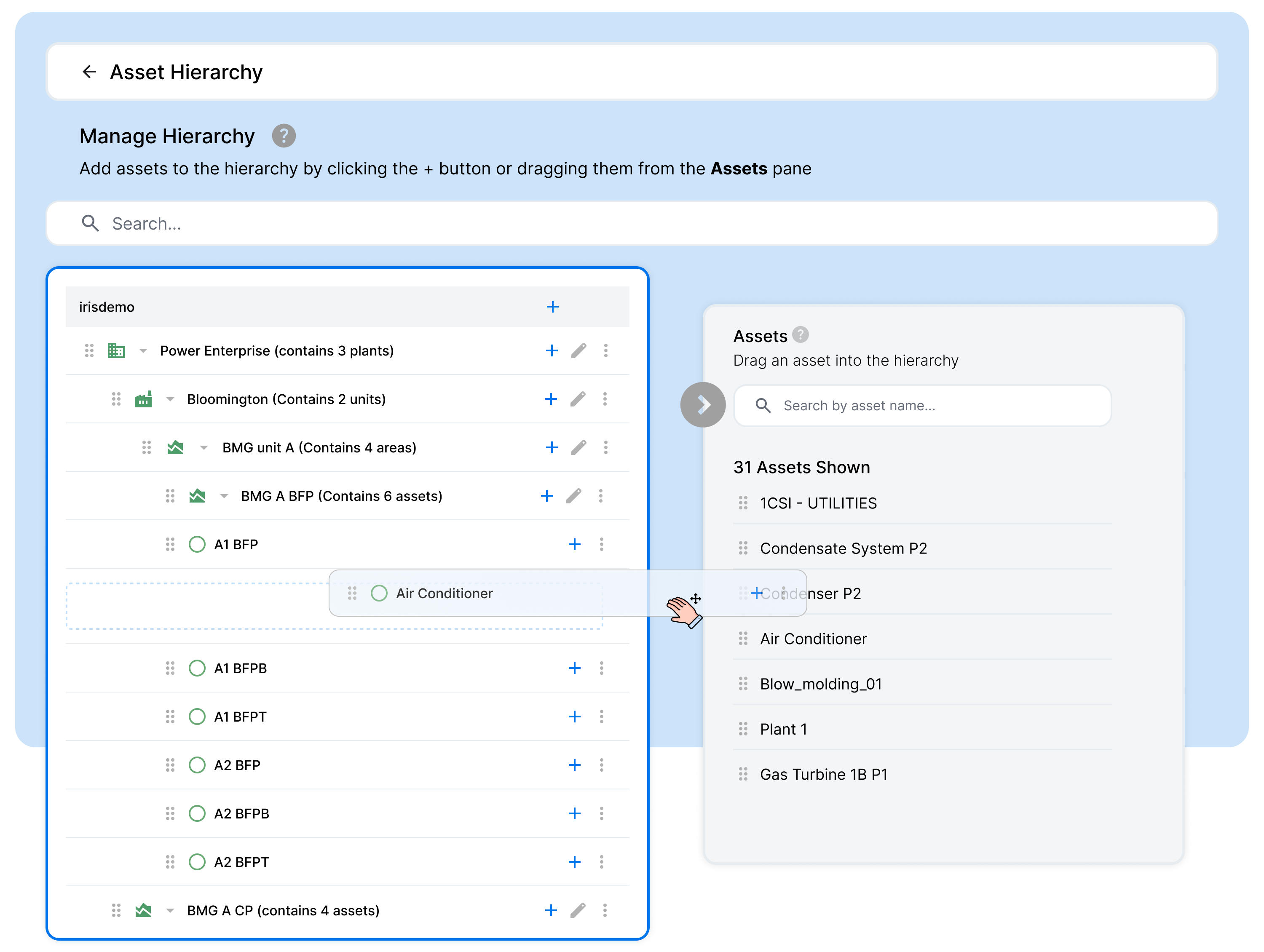
- Composability and modification of established relationships – For success, business objectives must remain at the forefront. A particular use case may only require a subset of industrial data. For example, to increase throughput for a specific unit or production line, the initial hierarchy and subsequent knowledge graph may only contain a fraction of available information. Expanding this structure must be manageable by the personnel onsite. For this, SymphonyAI provides a built-in drag-and-drop interface so domain experts with the proper permissions can modify the existing relationships and grow the hierarchy to new units or production lines over time.
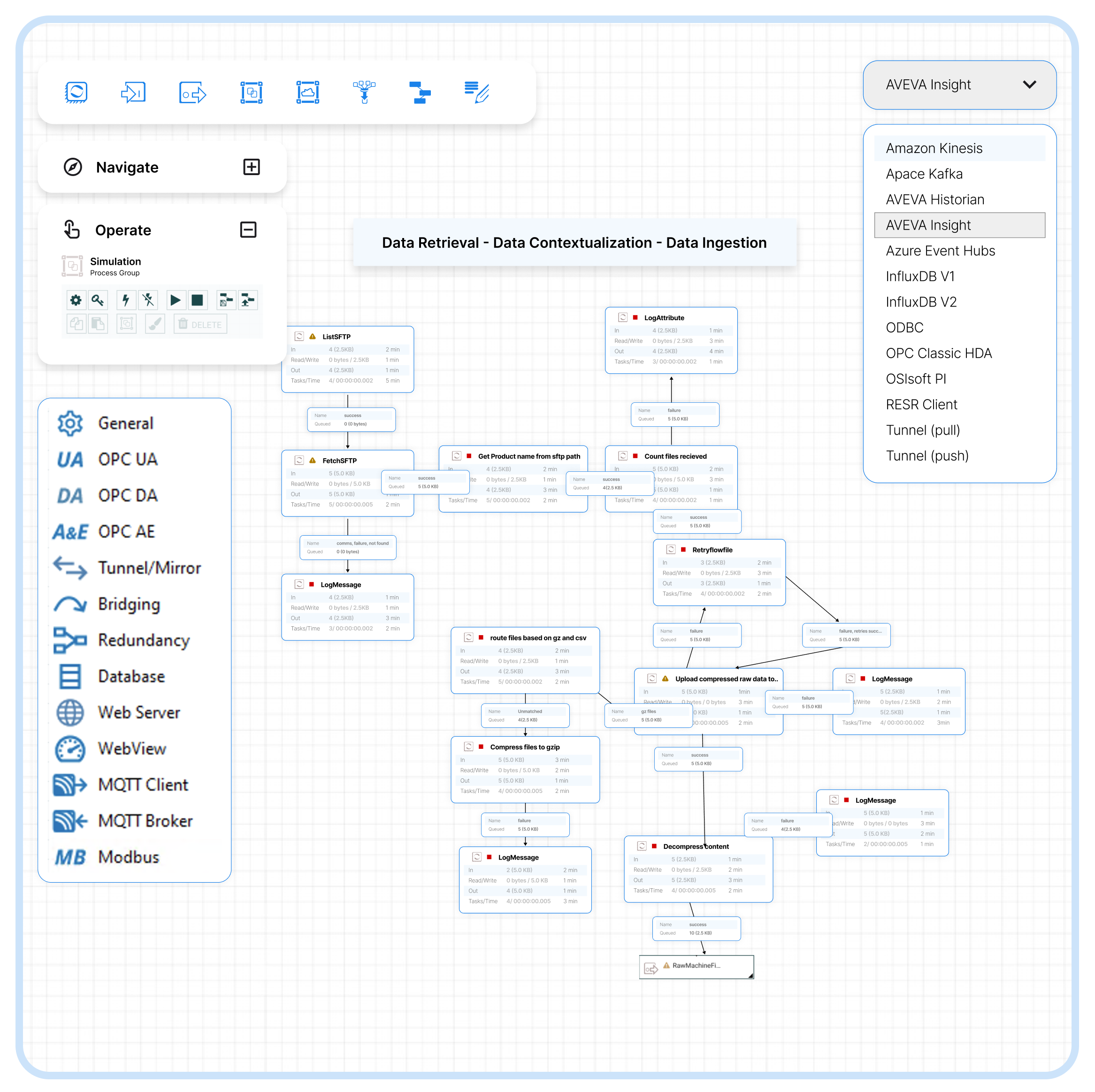
- Contextualization Pipelines – Mapping the initial data to the corresponding assets is a one-time event. With a composable approach, new data can be added over time. Without contextualization pipelines, the mapping process must be repeated each time new data is added from existing sources, so maintaining the industrial knowledge graph becomes unmanageable at scale. SymphonyAI uses contextualization pipelines to turn initial mappings into identified rule sets. These rule sets automatically map new data to their corresponding asset. Once data from the first unit is mapped to their corresponding assets, expanding to a second unit can reuse the same rules and be completed in a fraction of the time.
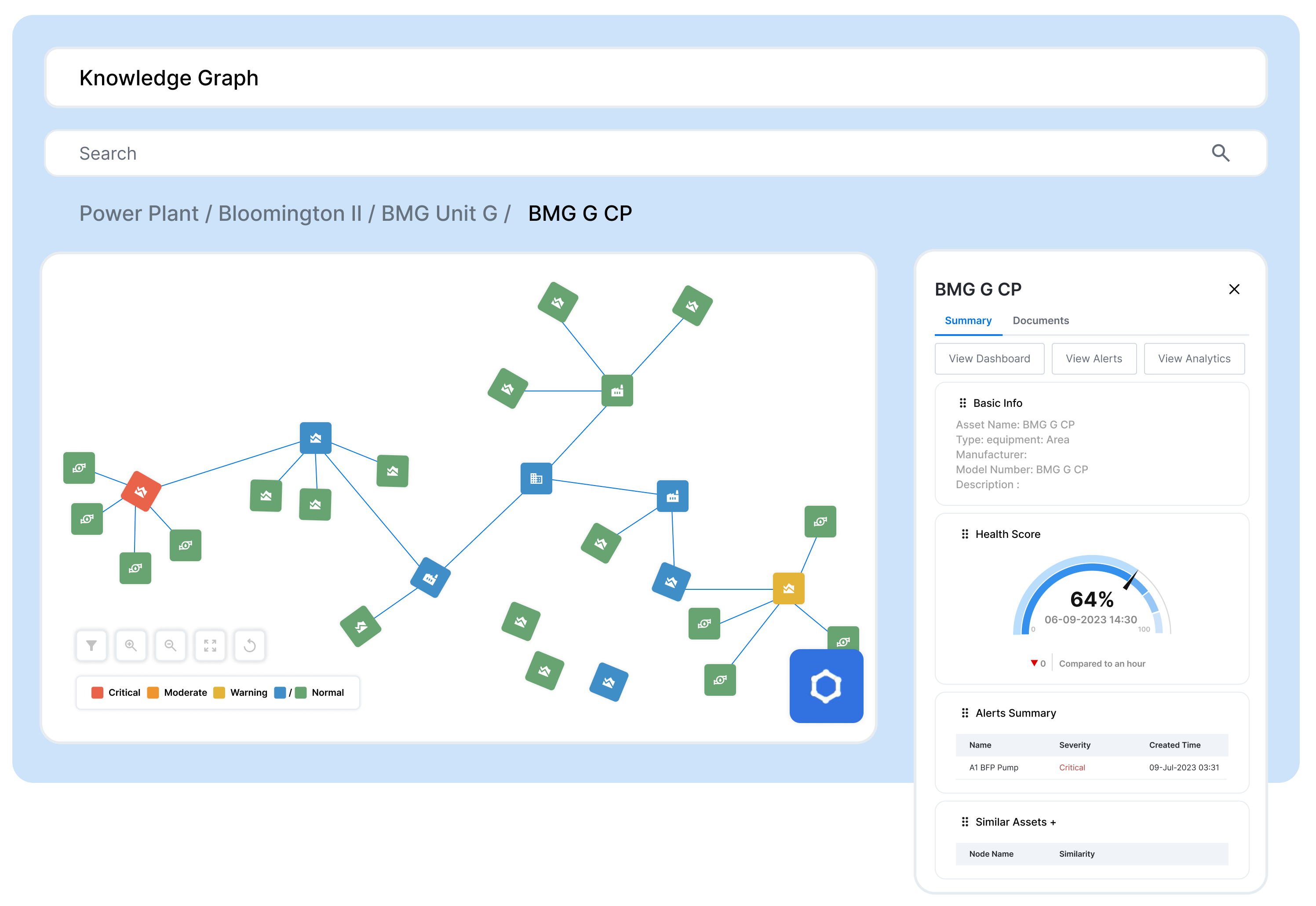
- Automated population of the industrial knowledge graph – With a dynamic asset hierarchy, the equipment profiles and relationships can be transposed into the nodes and edges of the industrial knowledge graph. Additional IT and engineering sources can then be mapped to the knowledge graph to further enrich it. The asset relationships represent one of many ways to structure data, and new relationships may need to be established to solve process or production-oriented use cases. As an example, SymphonyAI’s industrial knowledge graph extends the relationships between assets to include representations for mass and energy transfer, unlocking production and energy efficiency use cases.

- Generative AI data exploration – As an industrial knowledge graph continues to grow, standard searching and filtering are helpful but limited in the data they can surface. Searching by a specific asset or description may not yield all the results a user is seeking. To enhance knowledge graph exploration, SymphonyAI combines role-based views with a built in a generative AI copilot so users can perform searches in natural language. Instead of search by a specific asst name, search for “list all of the alerts for pumps in my area” and quickly find actionable information within the continuously evolving industrial knowledge graph.
Generative AI data exploration – As an industrial knowledge graph continues to grow, standard searching and filtering are helpful but limited in the data they can surface. Searching by a specific asset or description may not yield all the results a user is seeking. To enhance knowledge graph exploration, SymphonyAI combines role-based views with a built in a generative AI copilot so users can perform searches in natural language. Instead of search by a specific asst name, search for “list all of the alerts for pumps in my area” and quickly find actionable information within the continuously evolving industrial knowledge graph.
To learn more and see this process in action, watch the demonstration:
Sources:
1. https://www.idc.com/getdoc.jsp?containerId=US48669522
